Contents
7~8年ほど前から語学系のアプリ開発、語学そのものの興味から単語帳や単語のデータでフリーで使用できるものがないかを調査していました。今までは個人で使用してきたので、なぁなぁで済んでいたのですが、今後はアプリの機能として公開・データの使用を考えています。
また今まではあまりフリーのライブラリを使用したツールを公開していなかったので、ライセンスもあまり気にしていませんでしたが、それらのライブラリを使用するようになり、正しくライブラリを使用したほうが利便性が高くなります。そうなってくると正しくライセンスを表記の重要性が増してきました。 (もっと早くライセンスの正しい表記を勉強して、ライブラリを正しく使えるようになっていたらと後悔しています。ある種食わず嫌いで避けていた面がありました。)
まずは 以下の発音記号アドインで使用できないかと考えています。 特に読みのデータについてをまとめます。
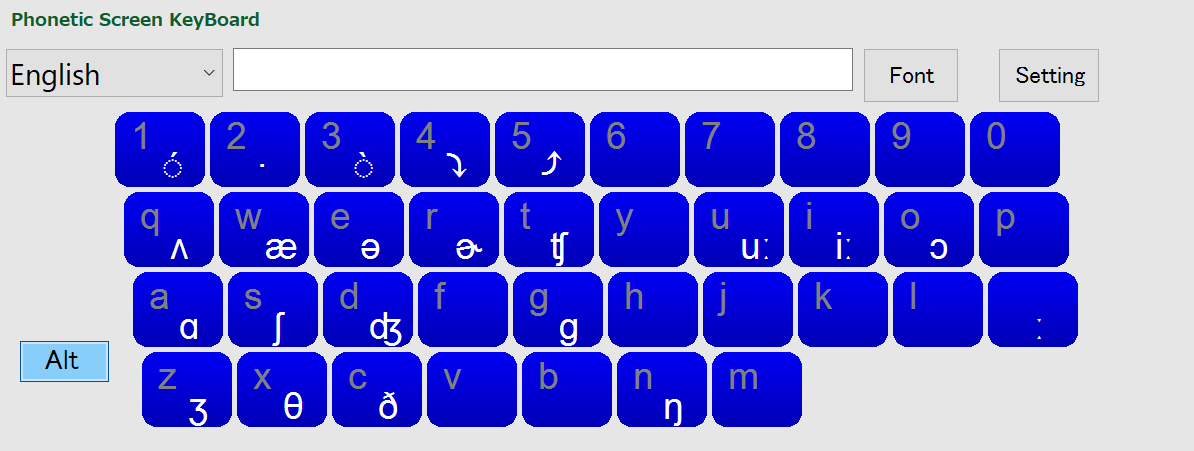
CMUDICT (英語)
カーネギーメロン大学の発音記号辞書データです。最近はGithubに管理が移っているようですが、発音記号辞書の辞書としては、これは外せません。
ライセンス
GithubのCMUDICTライセンスと見比べてみると、「二条項BSDライセンス」とほぼ同じ。二条項BSDライセンスの訳文として、参考例のリンクを挙げておきます。
語数
13万5000語程度
使い勝手
ライセンスが 二条項BSDライセンス なので、だいぶと使用しやすい感じを受けます。またGithubから.zipで展開すれば普通の単語と発音記号(変換要)のペアなので使用はしやすい。
Wikionary (英語・その他)
Wikipediaの姉妹プロジェクトで、類語辞書。また公式から引用すると以下。
ウィクショナリー (Wiktionary) は、コピーレフトなライセンス・オープンコンテントの辞書兼シソーラス(類語辞典)を作成し、配布することを目的としたウィキメディア財団によるプロジェクトである。
https://ja.wikipedia.org/wiki/ウィクショナリー
ライセンス
GNU Free Documentation License (GFDL) およびクリエイティブ・コモンズ 表示 – 継承 3.0 非移植 (CC BY-SA 3.0) のデュアルライセンス
語数
600万語 (6,097,070) at 2019/08/15時点, 英語版
使い勝手
600万語は魅力的だけれども、数が多すぎてローカルに保存するにはデータが多すぎる。また日本語版(22万語程度)を展開してみたけれど、日本語版にしても関連データが大変多い感じがしたので、xml or SQLでのデータの取捨選別に少し時間がかかりそう。(展開はこことここを参考にさせてもらいました。造語などもあるので、少しそういったものの選別も必要になる感じがします。)
Edict/Edict2 (英語)
オーストラリアのJim Breen氏が作成された辞書。Electronic Dictionary Research and Development Groupを参照。
ライセンス
語数
約14万語
使い勝手
一人で編纂されておられるので、Wiktionaryのようにまとまりのない感じはないかもしれません。中身を見ましたが、発音記号はなく、ロシア語・ドイツ語等の類語が表示されていました。今回の要件からはパス。
EJDict(英和)
パブリックドメインの英和辞書データ (ejdic-hand)、kujirahandさんが公開されています。TXT形式は kujirahandさんのホームページからダウンロード。
ライセンス
語数
65,600件(4.3MB)以上
使い方勝手
一番緩いライセンスなので、比較的使いやすいかと思います。Githubでも公開されているので、間違われていた時の報告もしやすい。 発音記号はなく、 今回の要件からはパス。
異体字データベース
漢字の読みについて調べていると、同じ意味の漢字でも異なる書き方・時代・地域で異なる文字で書かれている漢字があります。具体的には、日本・ 中国(簡体字)・台湾(繁体字)・韓国で異なる場合もあり、また日本語の中でも異なる場合もあります。これをデータベース化されています。漢字データベースの中の異体字データベースです。(漢字データベースプロジェクトの中の一環)
ライセンス
MITライセンス (異体字データ)
使い勝手
異体字データベースは使いやすいMITライセンス。またGithubで管理されておられますので、使い勝手は良いかと思います。あとは変換を各言語で実装されてるページを参考にすればかなり使えそう。
- 異体字同一視検索を実装メモ(C#)
- 異体字同一視検索(PHP) [下記でも紹介の北辞郎関連ページ]
文字数
一つのファイルで大きいもので1万8000程度。その他、3000文字程度のファイルもあるので、そこそこの分量があります。
UniHan
Unicode.orgが公開している漢字のデータベース。データベースの定義と元のデータもかなりしっかり管理・表示されており有用です。データのダウンロードはこちらから。UniHan.zipを探してダウンロードしてください。
ライセンス
UNICODE, INC. LICENSE AGREEMENT – DATA FILES AND SOFTWARE を参考にしてください。MITライセンスに近いです。 利用規約等も参考にしてください。
使い勝手
MITライセンスに近いので、ライセンス自体は使い勝手はよさそうです。U+XXXXの形から変換の必要ありますので、処理が必要という意味では少し劣るかもしれませんが、変換関数等を用意しておけば何の問題もありません。(テストコードも書いておけば、OKかと思います。)
文字数
読みだけで 18万8000程度(日音訓、台湾、中国、韓国含む)異体字等のデータもあり。
著作権切れの辞書(日本語)
Wiktionary:著作権切れ辞書の一覧を参考にすると日本語の著作権切れの辞書が検索できます。多くが国会図書館のサイトで画像データも公開されており、個人でデータ化するのは難しいかと思いますが、閲覧程度であれば問題なく可能。
他言語の辞書データとライセンス
いろいろと探してみるが、 パブリックドメイン的な辞書はそもそもあまりなく。転載不可の辞書サイトが見つかるだけ。
- 韓国語 → ほぼなし。あったとしてもリンク切れ。
- 中国語 → ほぼなし。「北辞郎」が唯一使えそう。最近らしくAPIなども用意されています。
さらに調査して、何かよさそうな辞書があれば追記します。 読みの辞書はないので、自分で調べてなんとかするしかなさそうです。
パブリックドメイン入りした教材など
パブリックドメイン入りした外国語学習教材で公開されていましたが、こういったものも参考になるかもしれません。
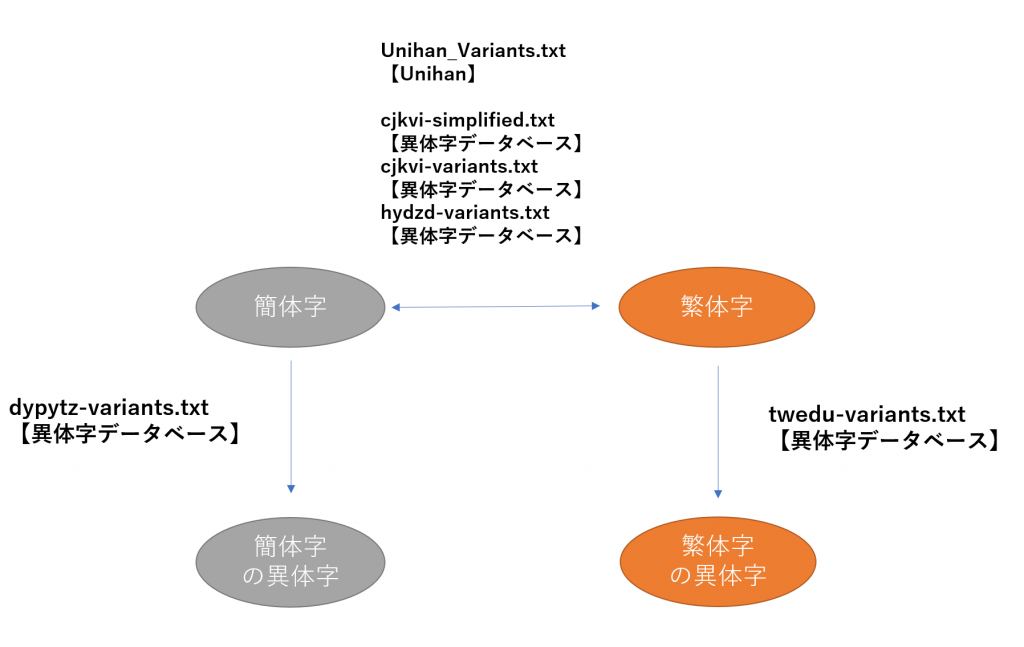
異体字について
文字で色々書いてもわかりにくいので、画像で貼り付けておきます。異体字データベースとUnihanを相補的に使用すれば、かなりの繁体字・簡体字の異体字データが使用できる気がします。

その次の方向性
こうなってくると次のデータとしての方向性は、単語のレベル等になってきます。専門性が高い単語なのか、生活に近い単語なのか等のデータがあればよいのですが。。英単語のレベルなどをもとに語彙のレベルや専門性・生活性などを元に単語を分類してもよいのかもしれません。これらは自分でやるしかないだろうと踏んでます。何か良い方法はないものか。。