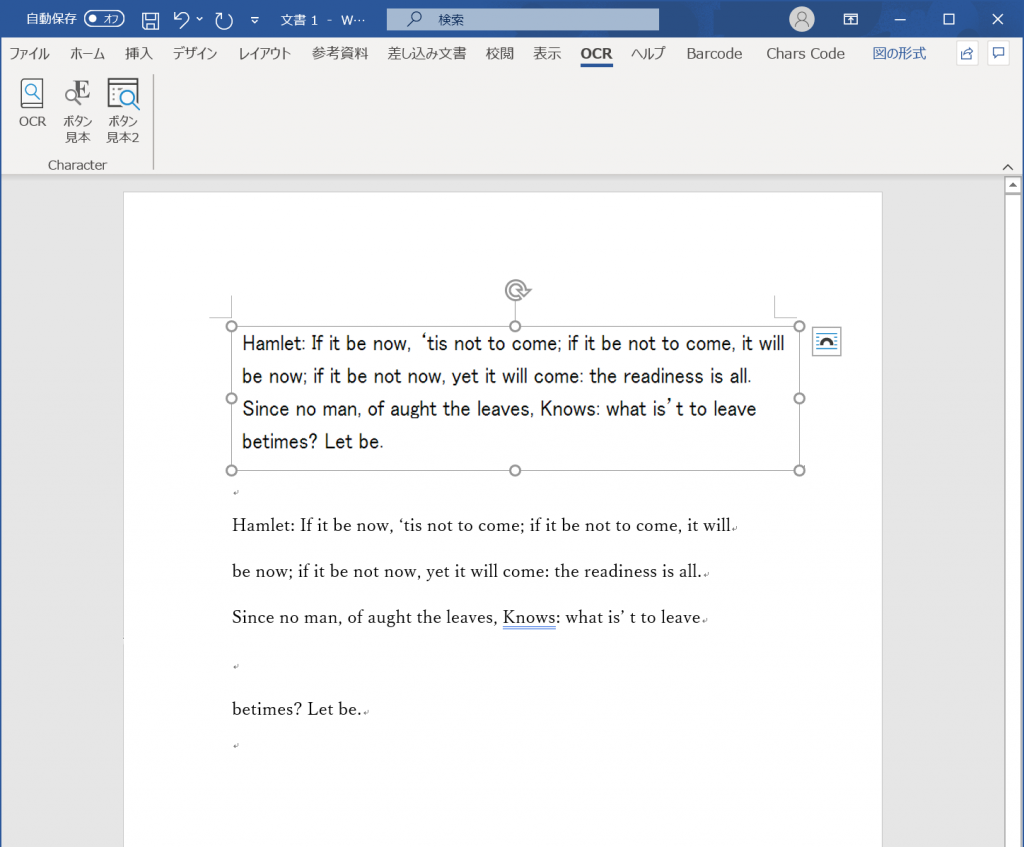
結果
過去の記事で、AndroidのOffice LensとかだとOCRできますという記事をかいたのですが、調査していくとTesseractというライブラリを使って出来そうということで、テスト+調査を繰り返し、最終的にWordでOCRをするアドイン仕立てにすることができました。無料でフリーのアドインです。
着想
過去の記事で、AndroidのOffice LensとかだとOCRできますという記事をかいたのですが、 Tesseractというライブラリが使いがってがよさそうでしたので、色々とやってみました。
途中経過
意外に簡単?にできそう?まぁ、ソースコードではごく簡単で、理想的な画像では簡単に実装できましたし、読み取った文字列を表示できました。他の画像での使い勝手が分からないところです。。精度や使い勝手がよかったら、エクセルのアドインにも仕立てあげられるなぁ。。
参考にしたソースはコードはこのリンクを参照しました。ありがとうございます。

英語のエンジンはこちらのGitHubからダウンロード。
テスト中のコードを晒してみます。殆ど工夫もへったくれもありませんが。。
// OCRを行うオブジェクトの生成
// 言語データの場所と言語名を引数で指定する
var tesseract = new Tesseract.TesseractEngine(
@"C:\tessdata", // 言語ファイルを「C:\tessdata」に置いた場合
"eng"); // 英語なら"eng" 「○○.traineddata」の○○の部分
// 画像ファイルの読み込み
var img = new System.Drawing.Bitmap(ofd.FileName);
// OCRの実行と表示
var page = tesseract.Process(img);
System.Console.Write(page.GetText());
//https://docs.microsoft.com/ja-jp/visualstudio/vsto/how-to-programmatically-insert-text-into-word-documents?view=vs-2019
// Wordにアクセスします。
Microsoft.Office.Interop.Word.Application word = Globals.ThisAddIn.Application;
object start = 0;
object end = 0;
//テキストの挿入
Microsoft.Office.Interop.Word.Range rng = word.ActiveDocument.Range(ref start, ref end);
rng.Text = page.GetText();
//画像の挿入
word.Selection.InlineShapes.AddPicture(ofd.FileName);
またいろいろテストしてみて、使いがって等を確認してみます。
追記
新しく学習データを作る際は、オフィシャルの方の学習ツールを使用する必要あり。C#ではラッパだけ。
こんな感じでCentOS上で.shで学習させている方がおられた。もうお一方。
現時点ではTesseract 4 での.shで学習させるのがベストっぽい。
後は、 Microsoft OCR(Windows.Media.Ocr)をWPF/WinFormsで使うかな。Microsoft OCR(Windows.Media.Ocr)は優秀だよというお話とか。
追記 その2
「図として保存」で有用なのは、パワポ・ワードぐらいなのですが、画像ならまぁ扱えそうなので、サクッと作ってみても良いのかも。。
追記 その3
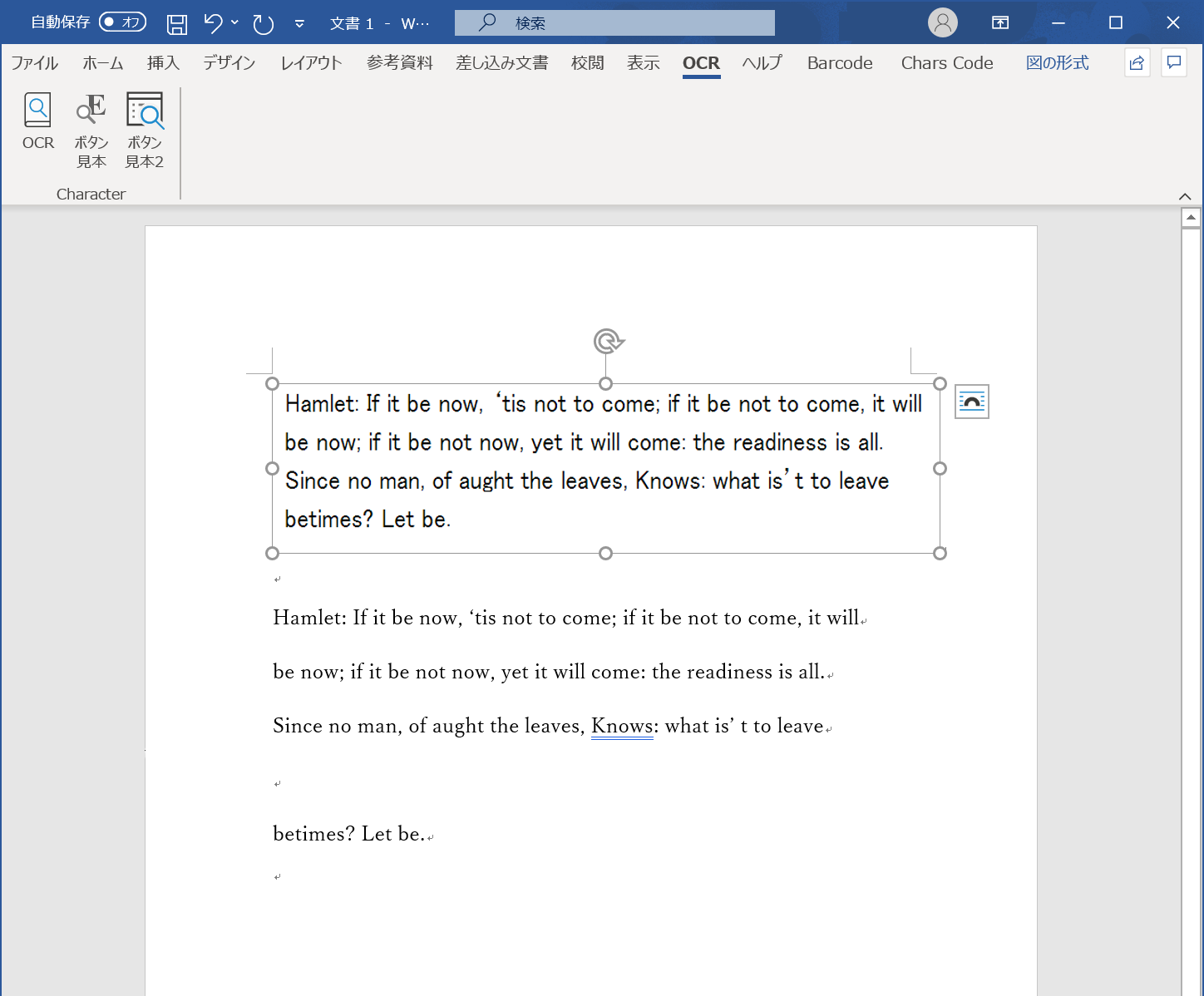
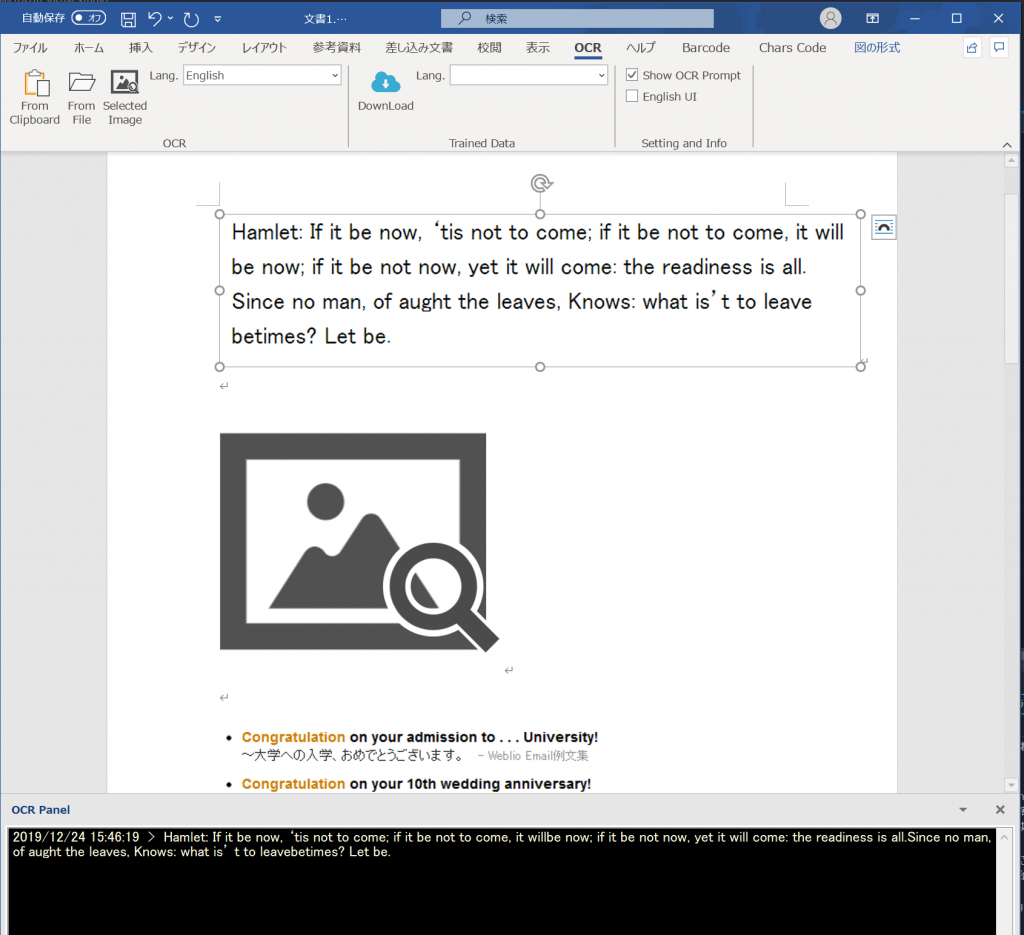
だいぶアドインの開発できてきました。まずはWordのアドインのみですが、英語のOCRはもちろん可能。
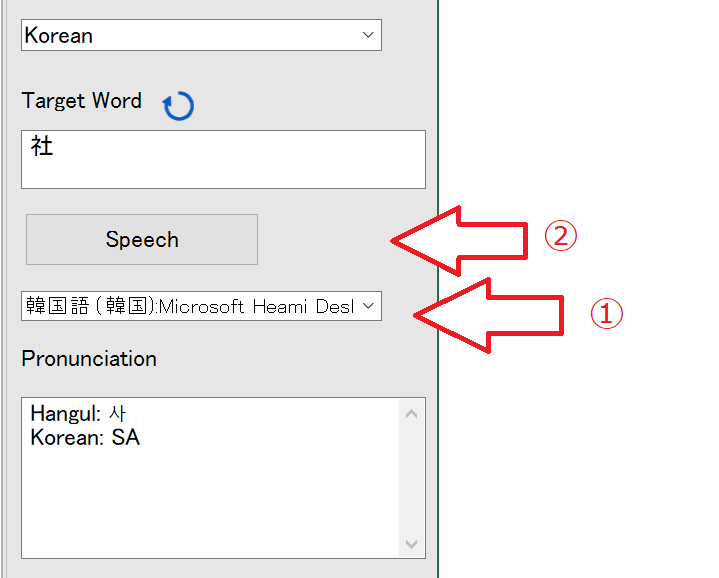
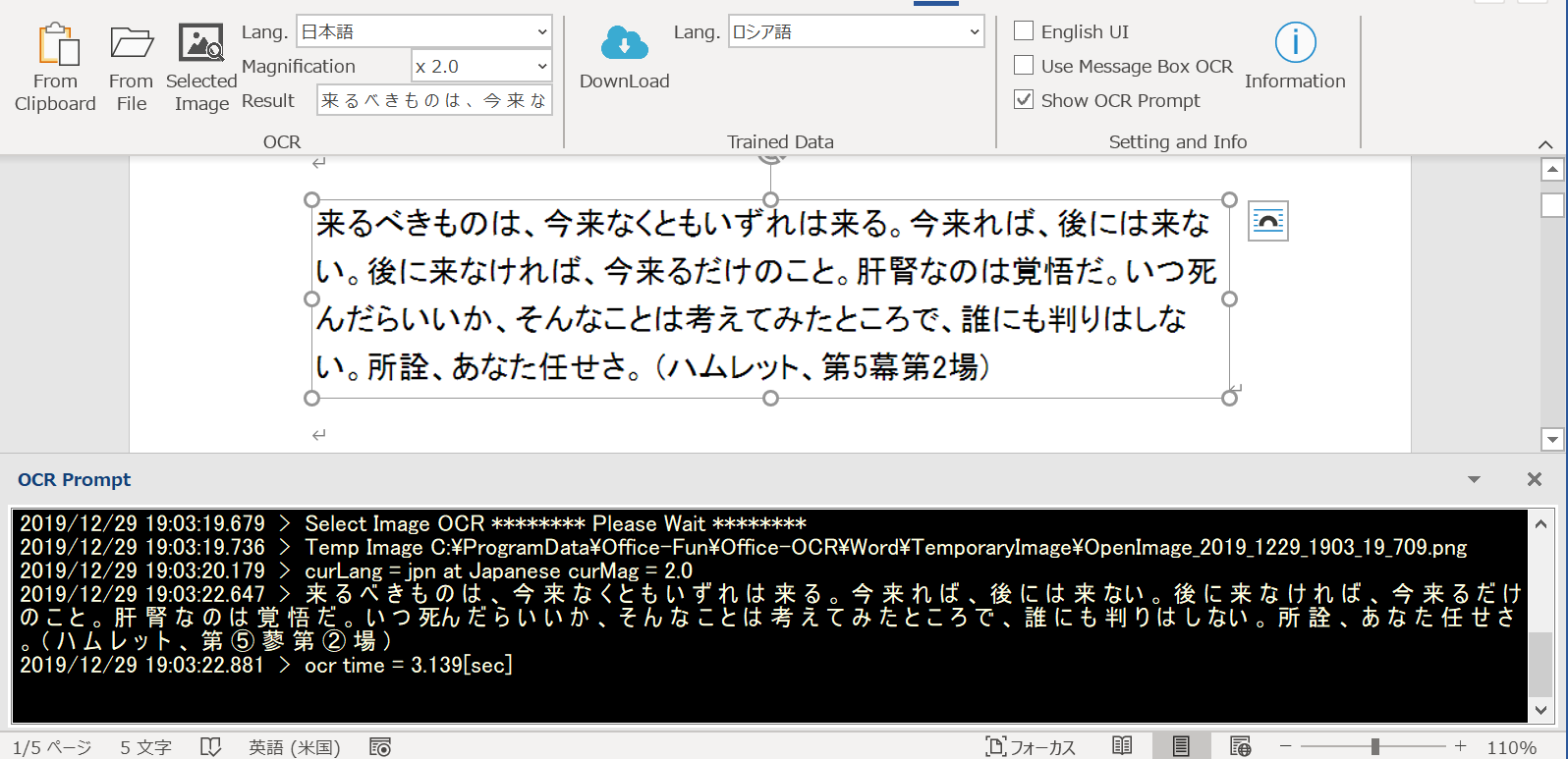
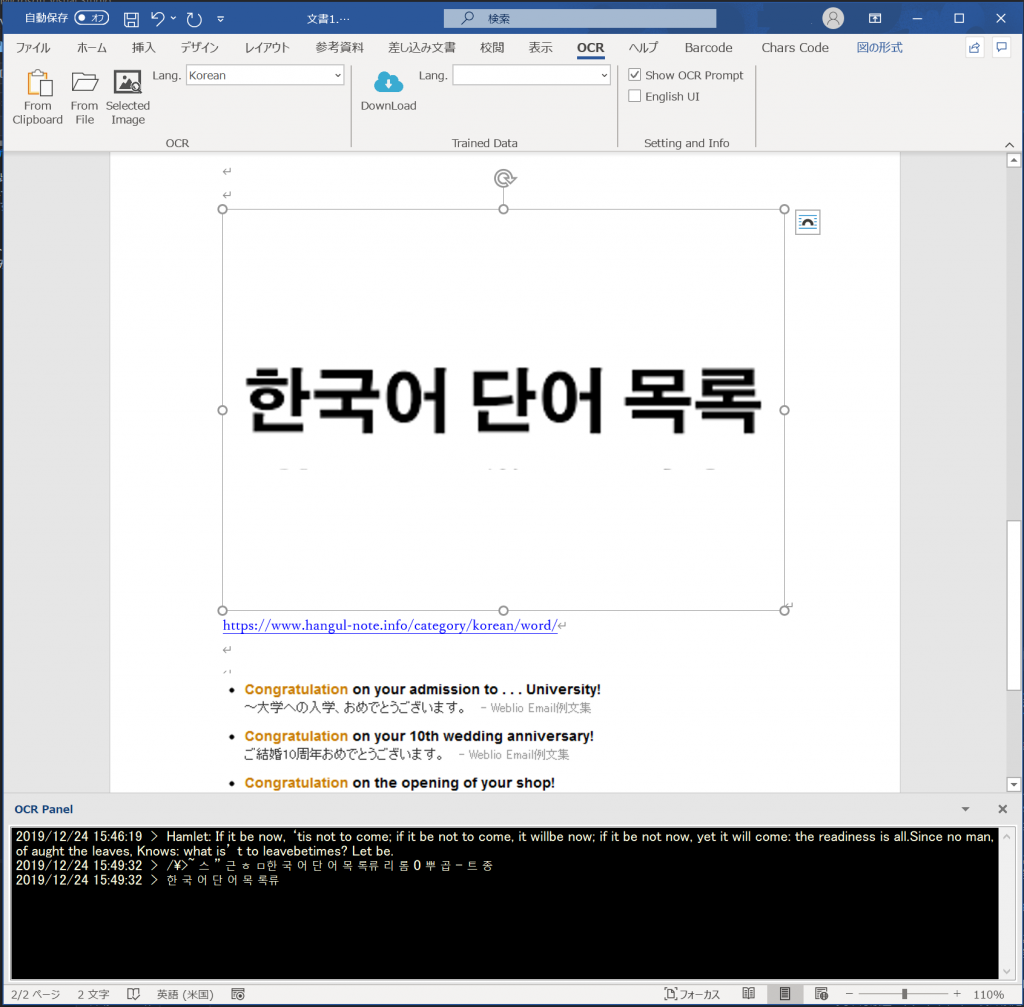
学習済みのデータもUIからダウンロードして、韓国語もOCRできるようになりました。(「韓国語 画像」で検索して、ここよりWordに貼り付けて読み取り。)
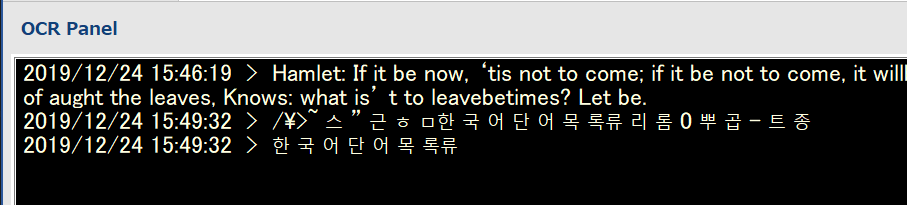
追記 その4 Word用アドイン完成しました
上記のような経緯を経て、最終的にWord用OCRアドインできました。冒頭の結果の部分をご覧ください。