Contents
どんなアドインか?
- 無料でフリーのWord用のアドインです。
- Wordに貼り付けた画像でOCRが可能です。
- 外部の画像でもOCR可能です。
- クリップボードにコピーした画像でもOCR可能です。(Windows標準のSnipping Toolとかで切り取ったPDFもOCR可能です。)
- 確認した言語では、英語、日本語、中国語(繁体字・簡体字)、韓国語、ロシア語でOCR可能。
- OCR可能な言語としては、上記も含めて129言語程度でOCR可能です。
- このアドイン(Office to OCR)はApache 2.0ライセンスで配布されている製作物が含まれています。
用途
特に想定はしていませんでしたが、 以下のような用途があるかと思います。
- 入力作業の効率化
- 言語学習の効率化
- 論文執筆・英語論文引用の際の文字入力効率化
- 文字起こし作業の効率化
- 保存データの検索効率化
どんな感じで文字認識するか?
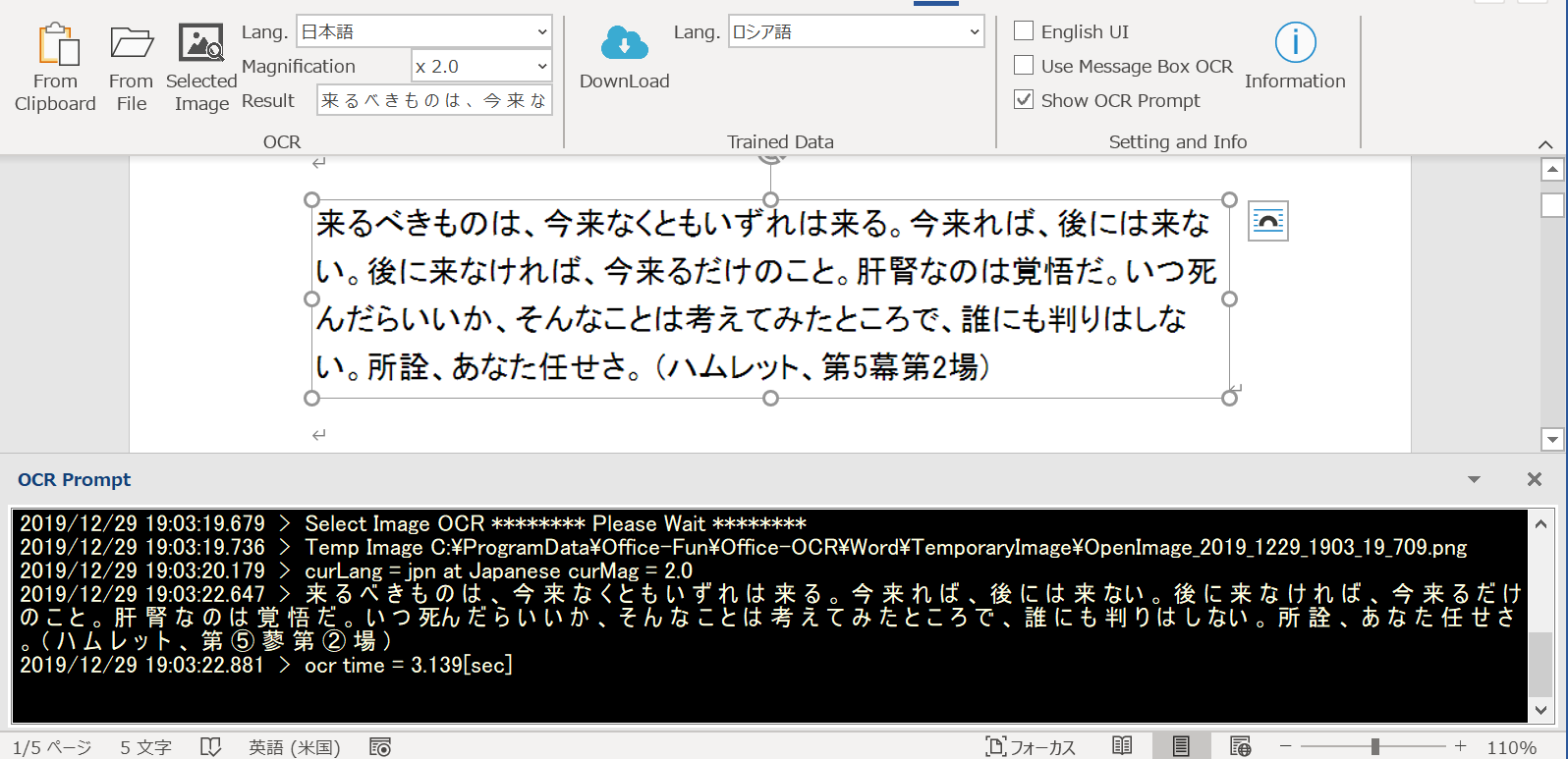
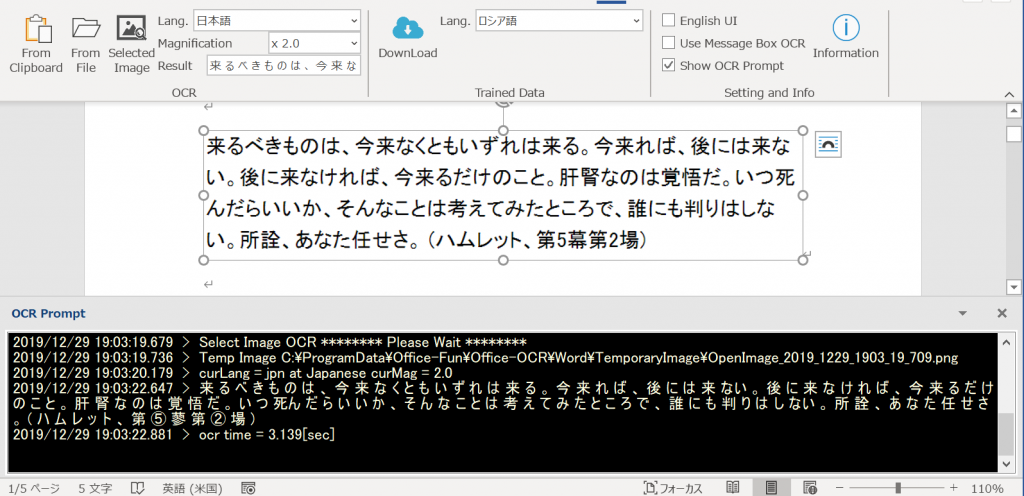
Wordに貼り付けた画像をクリック・選択して、OCRを行います。OCRの結果や、経過時間等を”OCR Prompt”と名付けたテキストボックスに表示します。認識した文字等は自由にコピペ可能です。
ダウンロード
インストール
インストールは以下のページを参照ください。
インストールが完了すると以下のようなタブがWord上に表示されます。


検出に向けたヒント・注意事項
ヒント
画像倍率(拡大率)をデフォルトでx2.0に設定しています。これは、画像認識率を大きくするためです。たまに大きすぎて認識が悪くなる場合がありますが、x1.0設定などにしてください。
注意事項
少し長い文章になると、OCRの処理に時間がかかり、本体側(Word)が反応がなくなる場合があります。(非同期処理を用いたので、大丈夫かとおもっていましたが、思惑が外れたようです。解析・改良に時間はかかるかとおもいます。)
適宜しようしながら、適当な範囲でご使用ください。
準備 – OCR学習済みデータのダウンロード
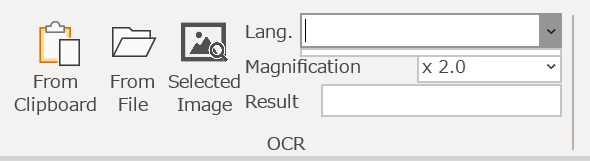
ダウンロード直後は言語選択のLang.のデータがありませんので、ダウンロードを行う必要があります。このように言語を選択できません。(OCRグループ― Lang.の部分)
Trained Data (学習済み)をダウンロードします。 Trained Data のブロックのLang.で『英語』等をダウンロードしてください。テストのために、中国語 繁体字、中国語 簡体字、英語、 日本語、韓国語、ロシア語をダウンロードします。
英語の言語名にしたいときは、English UIを試してみてください。
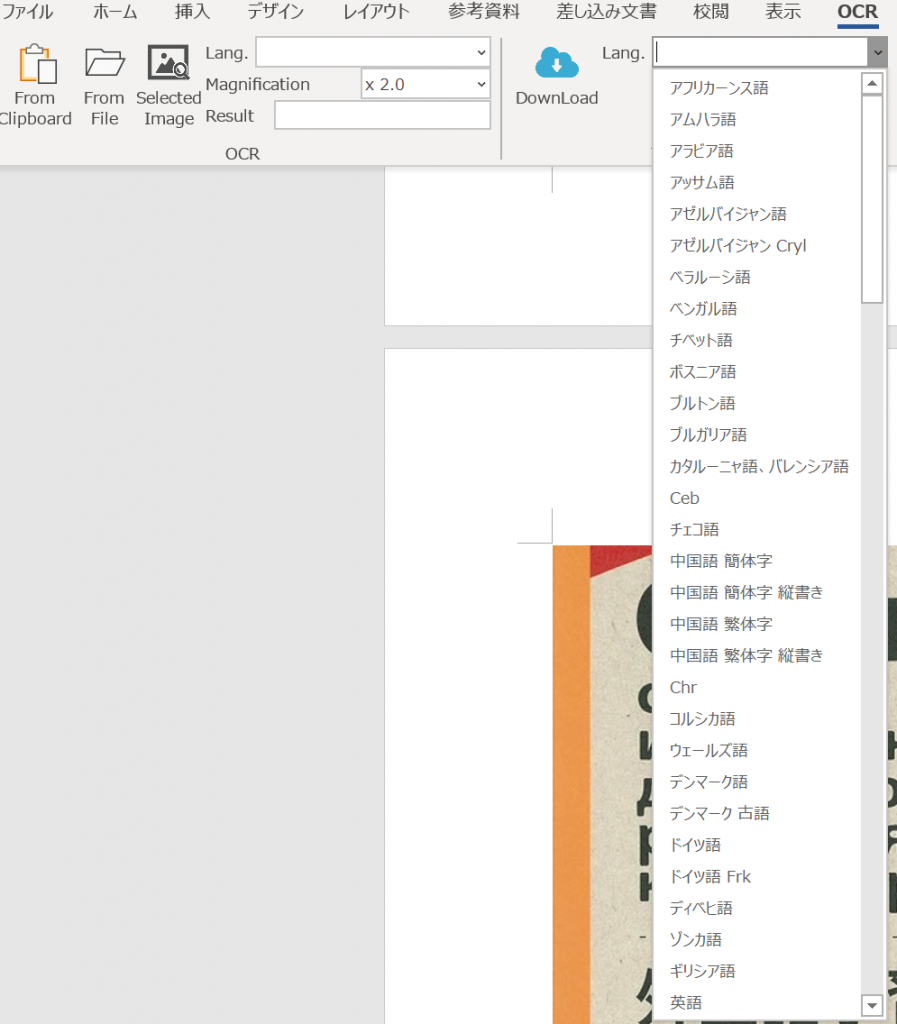
Lang.を選択して、”DownLoad”のボタンを押してください。
以下のようなメッセージが表示されると、ダウンロードが完了です。
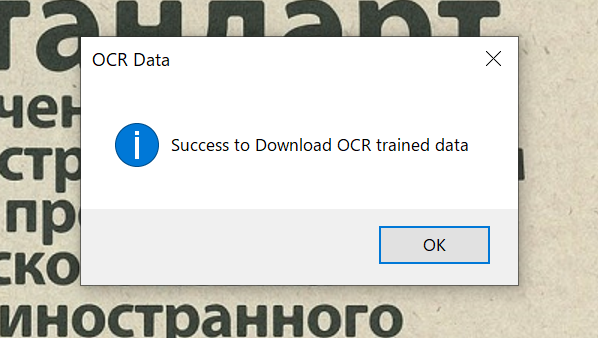
学習済みデータのダウンロードが完了すると、以下の様にOCRのグループ側の”Lang.”(言語)が選択可能です。
色々とダウンロードしてみました。
ちなみに学習済みデータはここから自動でダウンロードしています。
使い方 – Wordに貼り付けた画像をOCRする
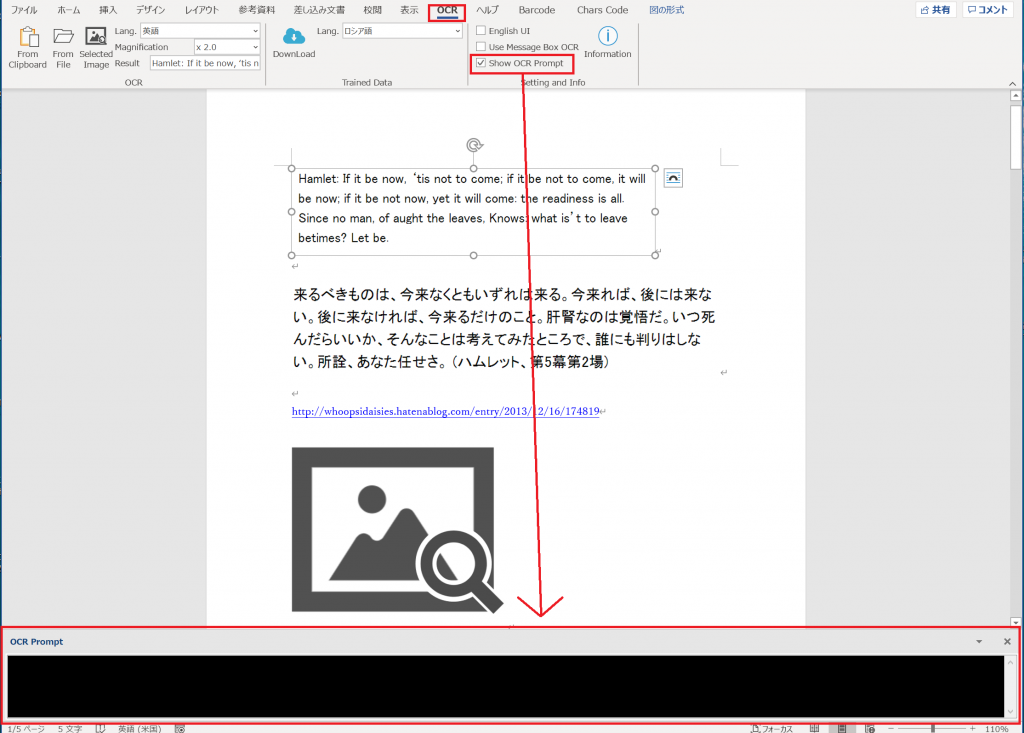
- “Show OCR Prompt”(OCR パネル表示)のチェックを入れてください。
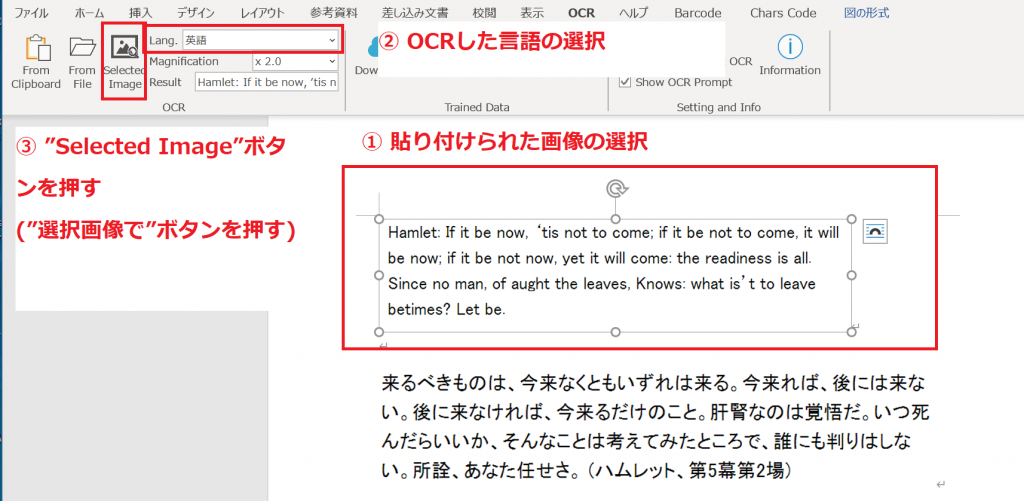
2. 貼り付けられた画像を選択してください(Wordの画像選択機能)。そして、OCRしたい言語を選択し、”Selected Image”ボタンを押すとOCRを開始します。
3. “OCR Prompt”パネルに結果が表示されます。そこから必要なテキストをコピーして、適当な部分に選択してください。
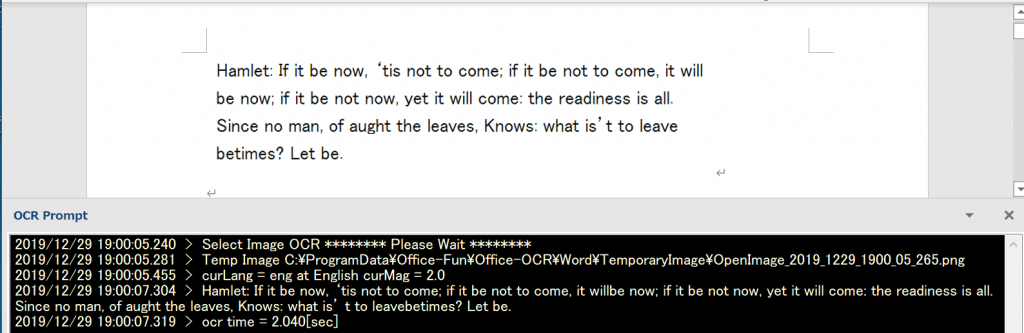
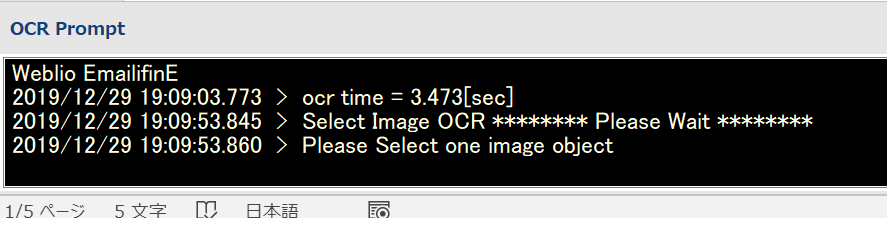
ちなみに、画像が選択されていない場合は、「Please Select one image object」のようなメッセージがPromptに表示されます。
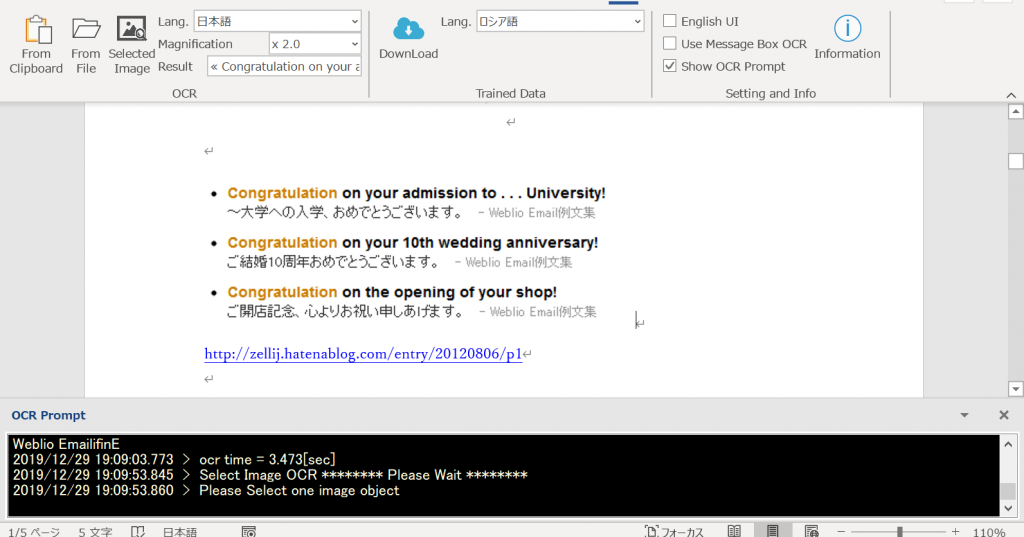
使い方 – クリップボードの画像をOCRする
この機能は、PDFが画像化されており、文字を選択できないような場合に有効です。例えば、このリンクのPDFでは文字を選択できますが、できないものとして説明を行います。
Windows10のSnipping Toolで画面の一部を切り取り、これをコピします。(クリップボードに)
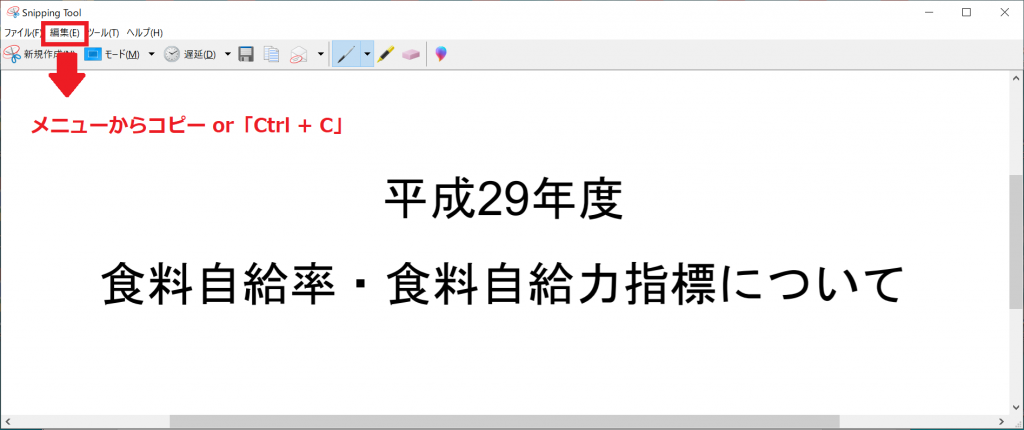
Lang.も忘れず選択し、メニューの「From Clipboard」「クリップボードから」をクリックしてください。
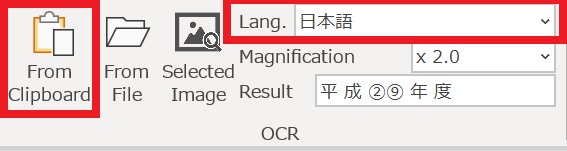
検出結果は以下のようになりました。実際にOCRしてみてください。

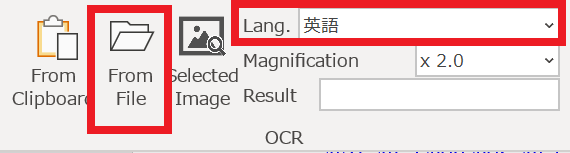
使い方 – 外部の画像を開いてOCRする
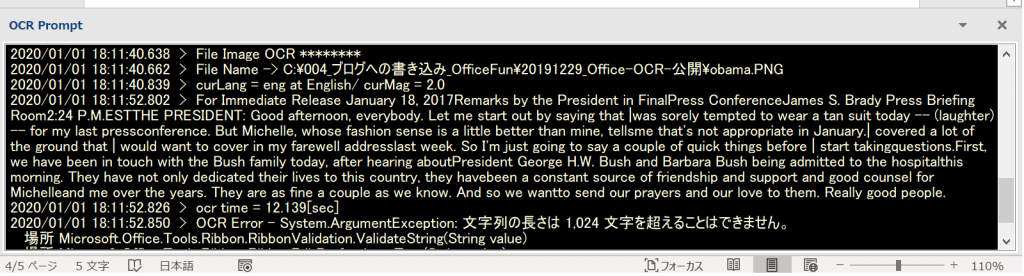
いい画像例がみつからなかったので、オバマ大統領の最後の演説のページを画像化しました。ここから画像化。

Lang.を英語で選択し、「From File」「ファイルを開く」をクリックしてください。画像選択画面が開きますので、保存した画像を開いてください。
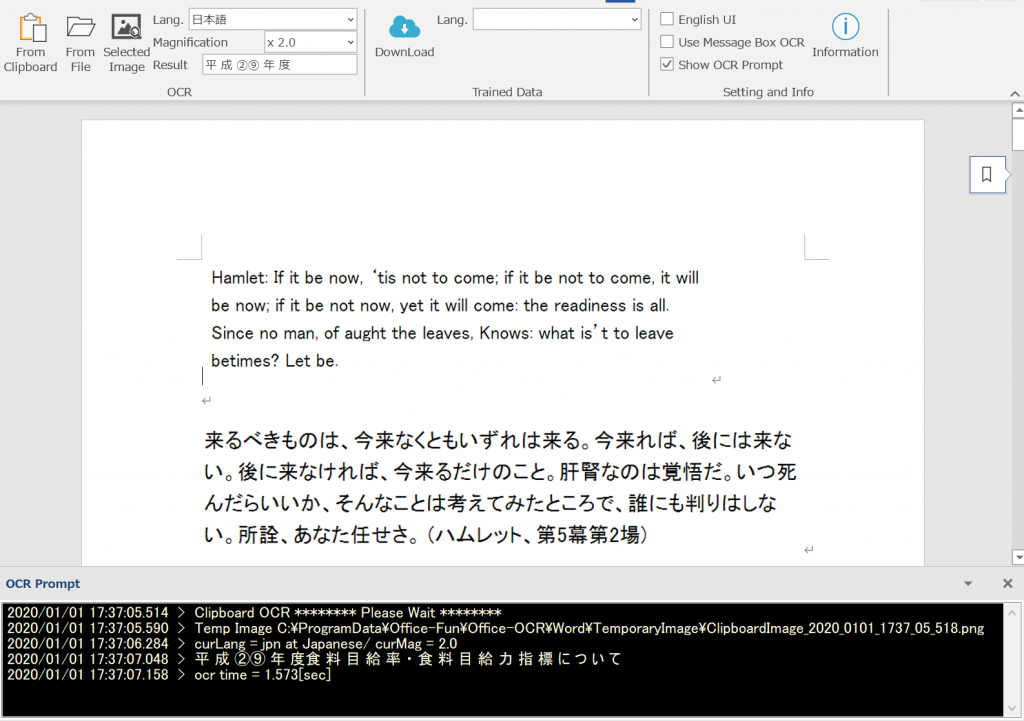
ちょっと長い文でよくばりすぎたようで、時間がかかりました。非同期という内部処理のため、本体(Word)側に影響はないかと思っていたのですが、長い時間処理するような場合は、少しWord側が停止するようです。
下の方にエラーと出ていますが、特に影響はありません。(OCR欄のResultへの書き込みサイズが大きいためにエラーが発生したようです。そのうちこのメッセージを出ないように直しておきます。)
使用結果 – 英語・中国語(簡体字と繁体字)・韓国語・ロシア語
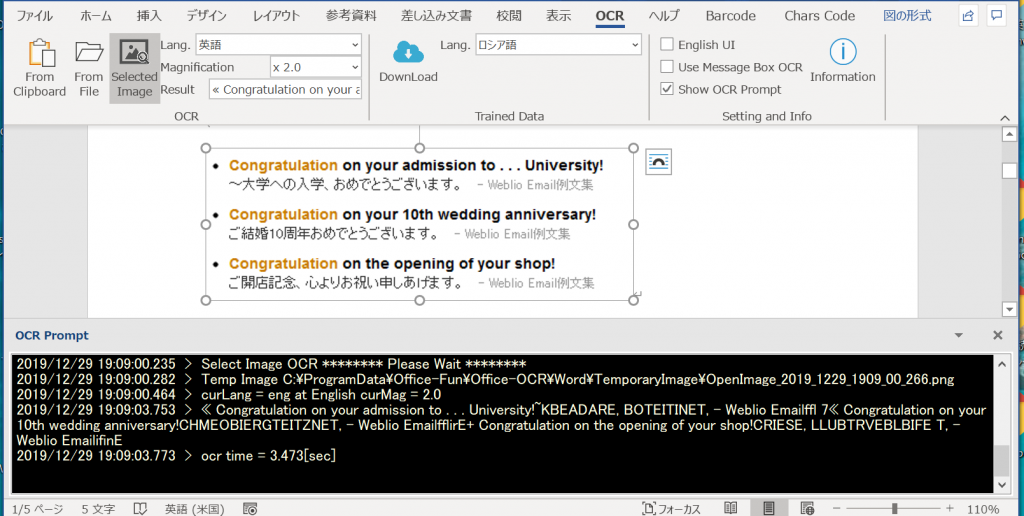
英語
このリンクより引用・ダウンロード。
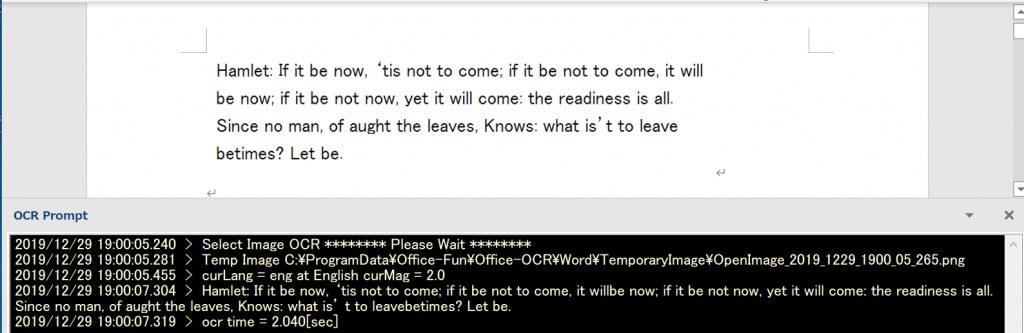
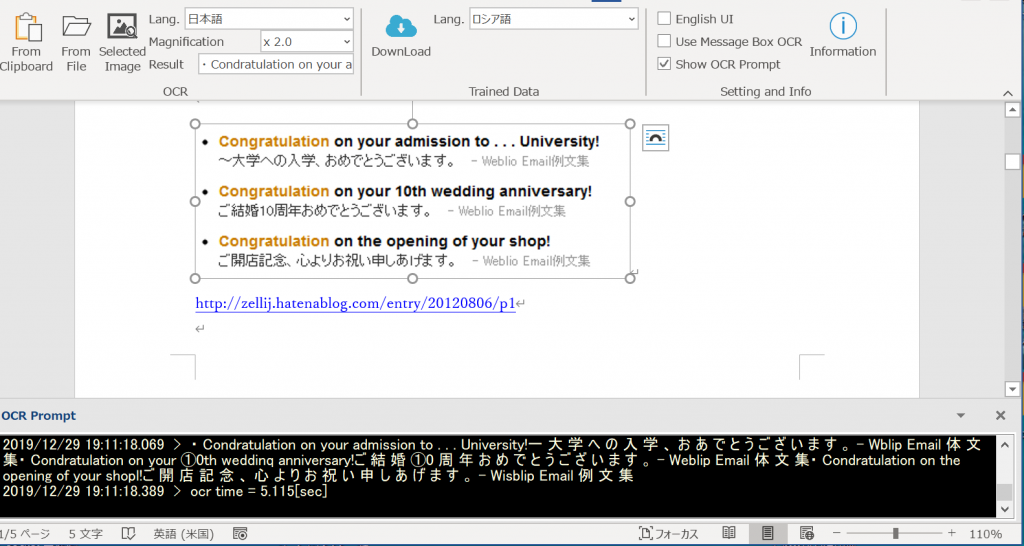
日本語
このリンクより引用・ダウンロード。
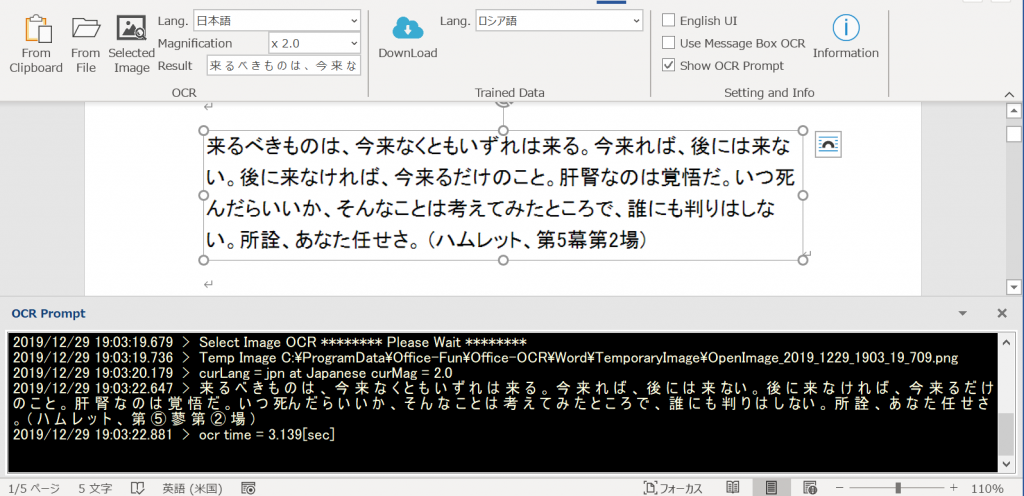
ここより引用。
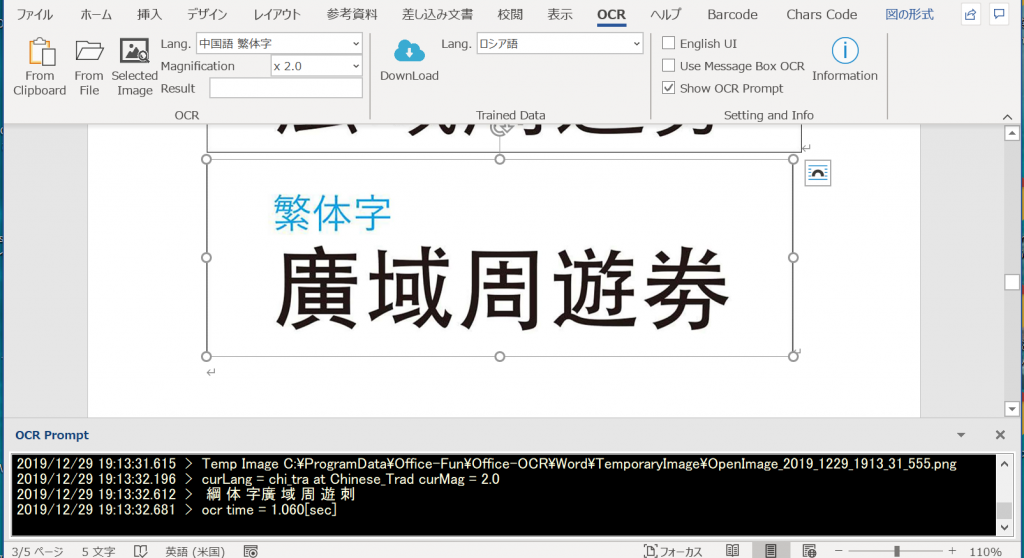
中国語(簡体字・繁体字)
大き過ぎると逆に誤検知するようです。(デフォルトの画像拡大率設定がx2.0になっているため。) ここより引用。
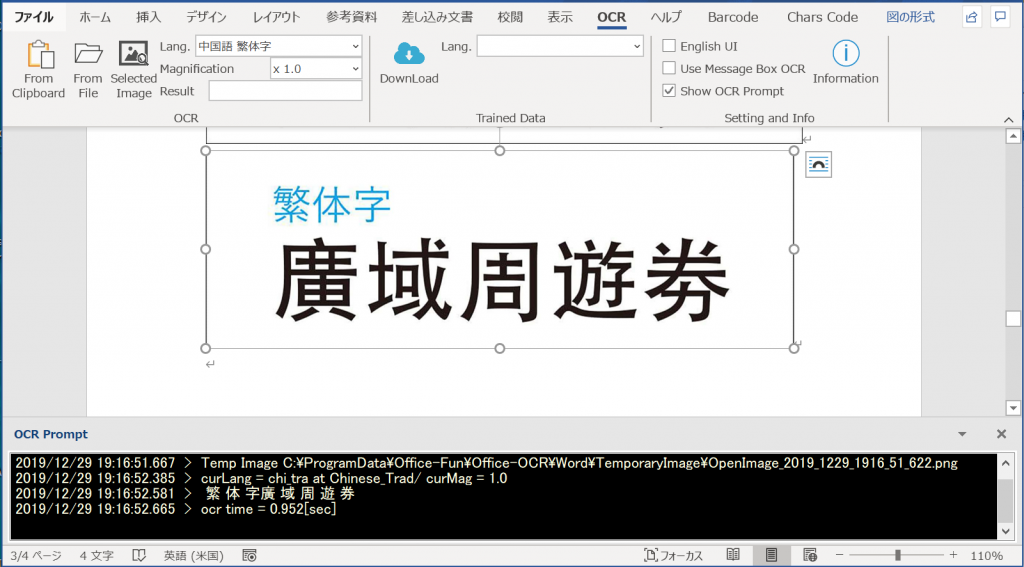
画像拡大率を x1.0に変更すると正しく検知できています。
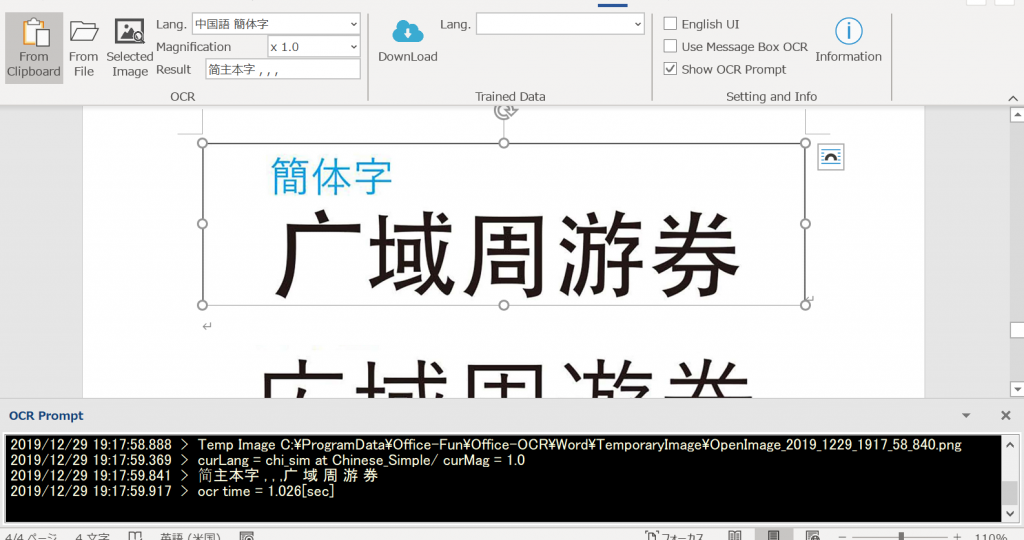
簡体字は少し同じ設定でも難しいようです。
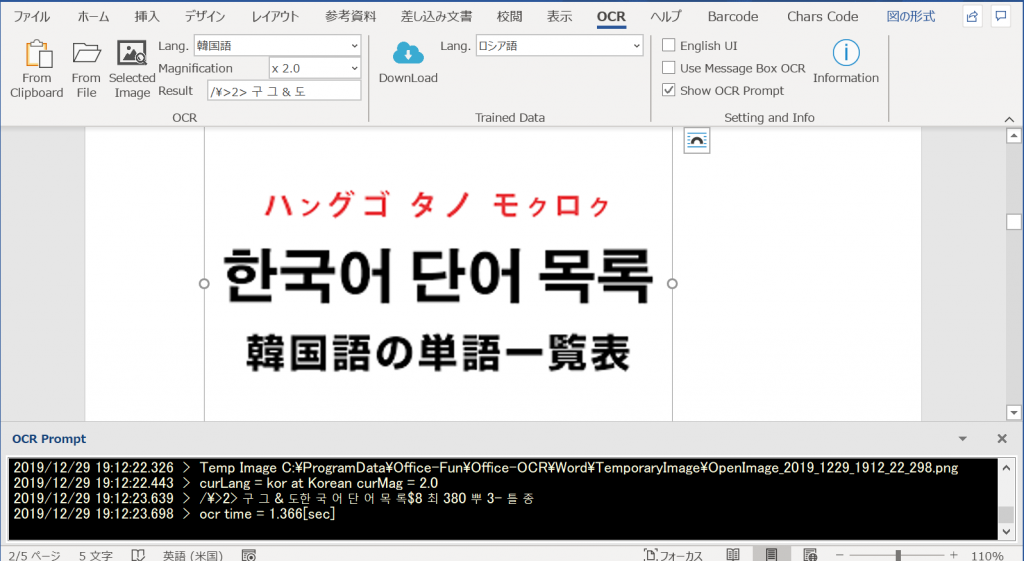
韓国語
ここより引用。
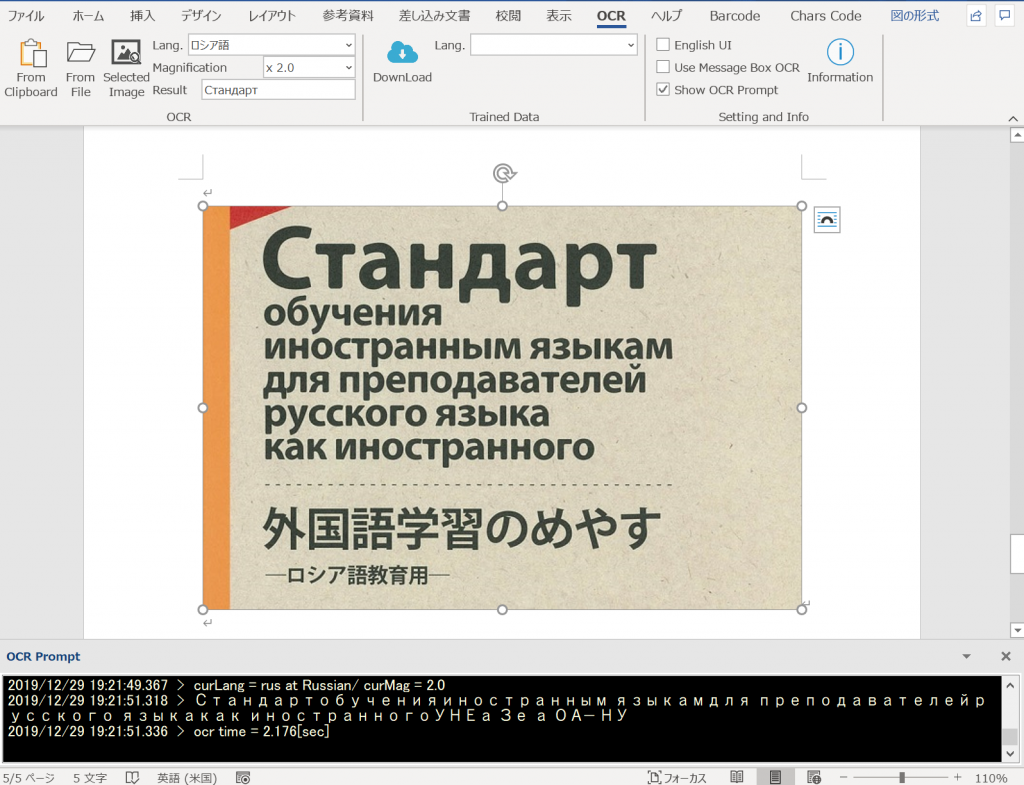
ロシア語
ここより引用。『ロシア語 画像』で検索。
まとめ
日本語・英語・中国語(繁体字・簡体字)・韓国語・ロシア語も含めてOCR可能でした。精度はある程度よく検出できていました。いろいろな画像で試してみてください。